

Cron jobs - We all need to use them. Anytime we have to schedule a task to run on some repeated schedule, our
old friend cron shows up, ready to work. They’re fairly easy for anyone to set up if they can write a script
and navigate their crontab (which usually involves a couple visits to crontab.guru).
However, you run into the following challenges:
-
Where do you run them? - Whether you run them on “that special box in the networking closet” or spin up an EC2 instance - that box is now a pet you need to care for, feed, and keep track of.
-
Retries - So - that special 3rd party vendor you get data from just happened to be doing maintenance during the exact window your job runs. Want to retry and make it more resilient? You have to build that into each of your scripts.
-
Resource Management - Uh oh - my ticketing import job just hogged 10GB of data and crashed the whole box - now NOTHING ran!
-
Monitoring - Hey, did my timesheet import job run at 12:30am today? Guess I’d better open up
/var/log/messagesand check. Oh no, it didn’t - why did it fail?!?!?! -
Secret Management - I hope nobody logs into my box and finds that credentials file I use to get into our Financial system…
Now, there isn’t a magic wand we can wave to simply make these problems go away. However, there is work we can do to bring these jobs to heel:
Kubernetes Cronjobs
That’s right - Kubernetes has a construct just for running cron jobs. By using the power of Kubernetes, you can ditch that special cron box and run your jobs as you would any other pod, alongside your microservices, web front-ends and other 12-factor applications. This solves a few problems:
-
Your job runs on the same Kubernetes nodes (or rather, “head of cattle”) as your other apps.
-
If your job needs to run again due to an exception, Kubernetes will resurrect the pod for you and run the job again.
-
The isolation you get with containerization, coupled with Kubernetes resource management, helps keep your job from trouncing anything else that needs to be run, should it go off the rails.
-
Your job can take advantage of Kubernetes Secrets out of the box - so those
exportentries in your.bashrcand credentials residing on your filesystem can go away. Extra points if you architect your pods to pull their secrets from Vault instead. -
Have a number of cronjobs to deploy? Use a common, configurable
helmchart. Each job (or group of jobs) can be its own container, and that container image can be a parameter to your chart. -
kubectl logsworks just as well for cronjobs as it does any other pod. You’re even better off if you’re piping your logs to a more queryable form, such as Elastic Search, Splunk, or NewRelic. Also, if you REALLY want to get more mileage out of your logging, many systems now natively support parsing JSON-formatted logs for more precise querying and alerting: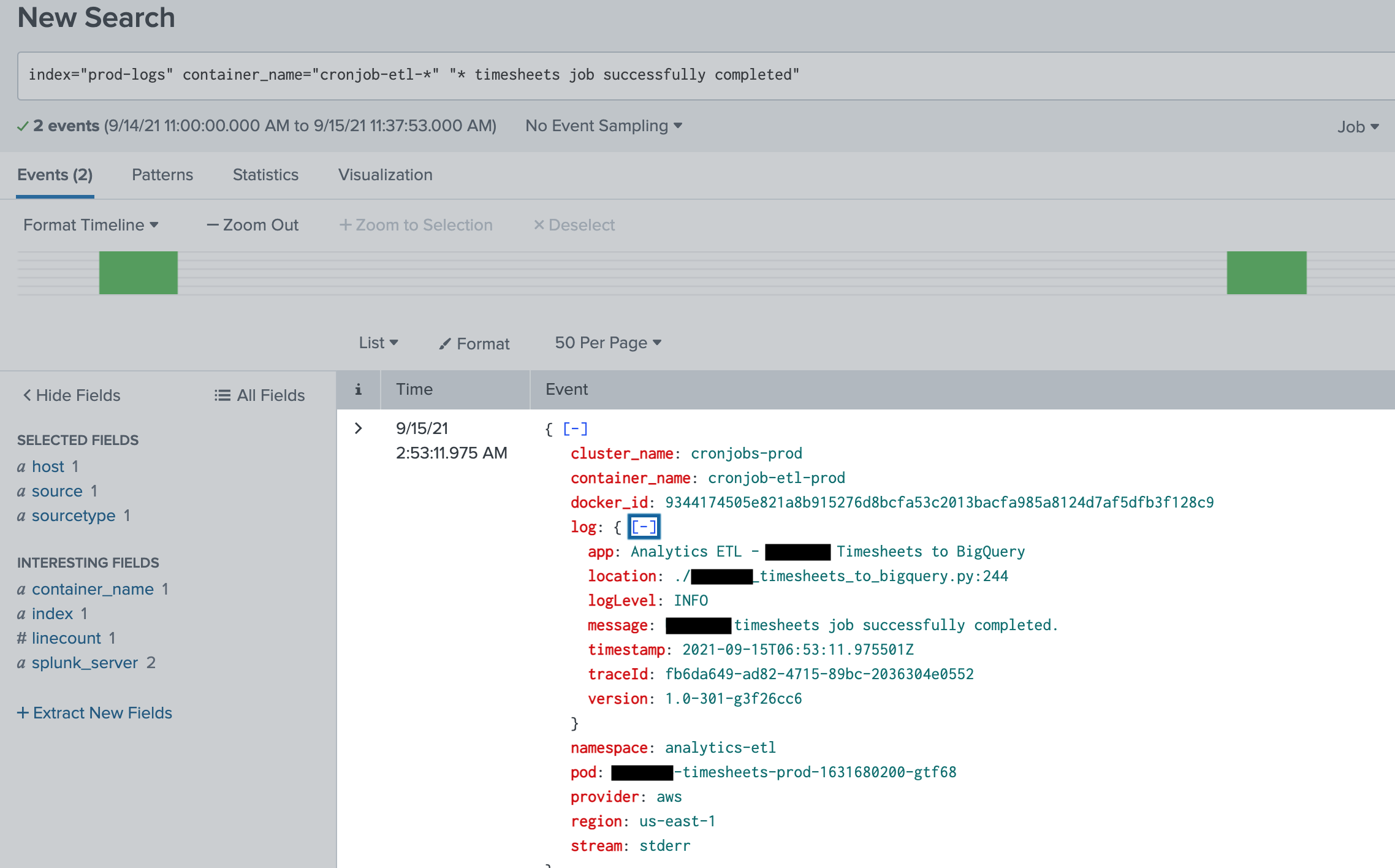
Terraform + NewRelic == Alerting Joy
Most sysadmins know it is better to be alerted when a problem occurs instead of being alerted by the customer when they notice something is wrong several hours later. Also, getting alerts “just right” can be a hastle, especially if you have to manually alter those alerts through some UI.
Enter Terraform: In addition to deploying your infrastructure, you can now deploy “alerts as code”. Need to edit alerts for 50 different cronjobs? Use terraform. As of right now, Terraform has providers for multiple different systems, including NewRelic and Splunk.
And what better place to manage your alerts-as-code than in the same repository as your actual application code and helm
configurations! If you play your cards right, your developers can help manage the alerts for their own applications. #DevopsCulture
CICD - Can I Cron Daringly?
Your carefully crafted script is an application. Just because it is a script run on a schedule instead of an API or front-end doesn’t mean it can’t benefit from things like automatic deployment and testing.
Here is a peek at one of our pipelines, which deploys one of our cron jobs:
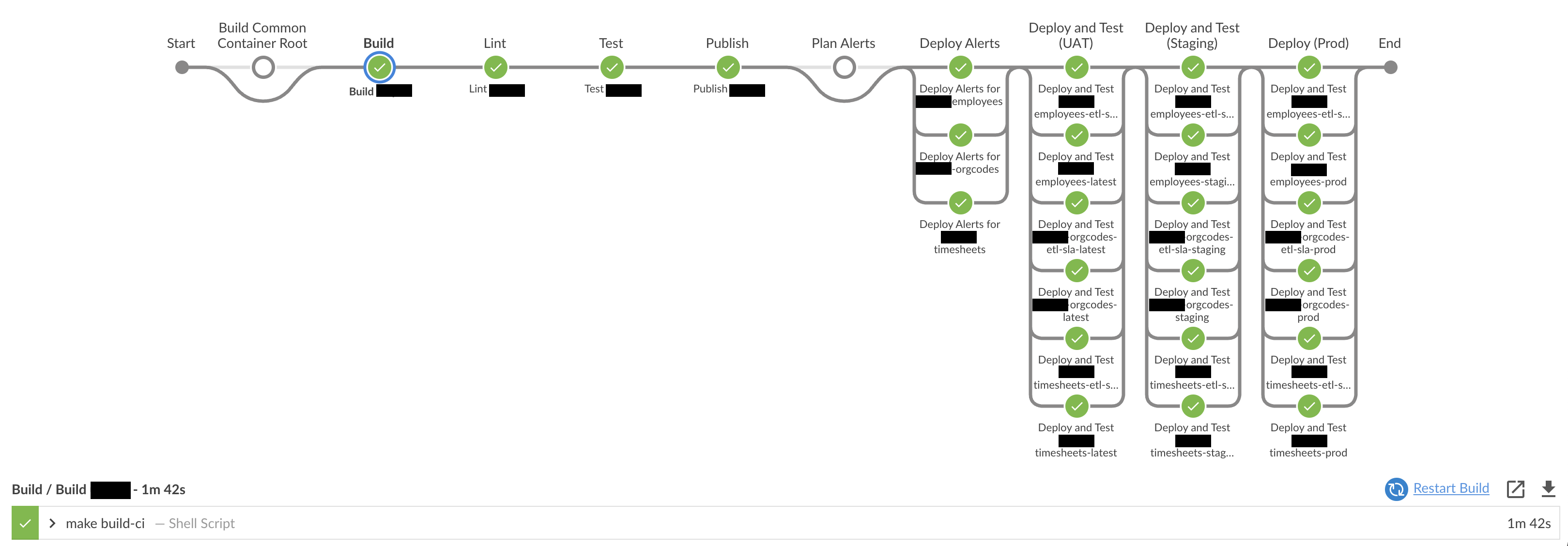
Aside from the gratuitous “redaction-fest”, you probably notice that there’s a lot going on here. This pipeline does the following:
-
Build a common root container (our repo has multiple cronjobs) to avoid duplicating code across jobs that do some of the same things.
-
Build the container that runs the cronjobs for a particular system from which we pull data.
-
Lint and test our code.
-
Deploy alerts.
-
Deploy our cron job and any “monitoring” jobs to each environment. In lower environments like UAT and Staging, actually run a limited test of the job to ensure it works.
Though this post has been largely high-level, we hope it gives you some ideas on how to change your cron jobs from a mob of possessed daemons into a group of efficient, well-monitored workhorses.




{kind=link}