

Before we get started, I’ll first list some basic information about the tools and technologies used. This is super quick and high-level, so be sure to consult documentation for more details:
Apache Spark
- Unified analytics engine for large-scale data processing
- Fast and general-purpose cluster computing system.
- Comes with higher-level tools including
- Spark SQL for SQL and structured data processing
- MLlib for machine learning
- GraphX for graph processing
- Spark Streaming Java Virtual Machine (JVM) based, Scala specifically
.NET
- Open-source, general-purpose development platform
- Cross-platform, flexible deployment
- Common Language Runtime (CLR) based
Docker
- Runs your code inside of containers
- Standard unit of software that packages up code and all its dependencies so the application runs quickly and reliably from one computing environment to another
VSCode
- Lightweight but powerful source code editor
- Has a rich ecosystem of extensions
Now that we’re done with intros, let’s take a look at a sample Dockerfile we will use to follow this guide on .NET for Apache Spark.
FROM mcr.microsoft.com/dotnet/sdk:6.0 as core
FROM adoptopenjdk/openjdk8:jdk8u292-b10
RUN curl -L https://archive.apache.org/dist/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz \
| tar -xzC /usr/local
# If you donwload the Apache Spark files separately, just add them
#ADD spark-3.1.2-bin-hadoop3.2.tgz /usr/local
RUN curl -L https://github.com/dotnet/spark/releases/download/v2.0.0/Microsoft.Spark.Worker.netcoreapp3.1.linux-x64-2.0.0.tar.gz \
| tar -xzC /usr/local
# If you donwload the Microsoft.Spark files separately, just add them
#ADD Microsoft.Spark.Worker.netcoreapp3.1.linux-x64-2.0.0.tar.gz /usr/local
COPY --from=core /usr/share/dotnet /usr/share/dotnet
CMD "ln -s /usr/share/dotnet/dotnet"
ENV \
# Enable detection of running in a container
DOTNET_RUNNING_IN_CONTAINER=true \
# Set the invariant mode since icu_libs isn't included
DOTNET_SYSTEM_GLOBALIZATION_INVARIANT=true \
# Set worker location to where it's downloaded to
DOTNET_WORKER_DIR=/usr/local/Microsoft.Spark.Worker-2.0.0
ENV SPARK_HOME=/usr/local/spark-3.1.2-bin-hadoop3.2/
ENV PATH=:${PATH}:${SPARK_HOME}/bin:/usr/share/dotnet
# Quiet down some Spark logging
RUN echo 'log4j.rootCategory=WARN, console\n\
log4j.appender.console=org.apache.log4j.ConsoleAppender\n\
log4j.appender.console.target=System.err\n\
log4j.appender.console.layout=org.apache.log4j.PatternLayout\n\
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n\n'\
> $SPARK_HOME/conf/log4j.properties
RUN chmod 777 $DOTNET_WORKER_DIR/*
This is starting from the two top layers, you start with the dotnet core SDK, you include the OpenJDK runtime, and then you add Apache Spark and the Microsoft Spark worker for spark dotnet, and some stuff in the middle to get stuff up and running.
If you’re running on a local machine you have to do this every time you update, there’s a version change, etc. The benefit of Docker is you don’t have to do that. You define it in the file, get it up and running very quickly, and have the environment do what you want with the right dependencies, very consistently.
Here’s the command:
spark-submit \
--class org.apache.spark.deploy.dotnet.DotnetRunner \
--master local \
MySparkApp/bin/Debug/net6.0/microsoft-spark-3-1_2.12-2.0.0.jar \
dotnet MySparkApp/bin/Debug/net6.0/MySparkApp.dll MySparkApp/input.txt
and then the output:
21/10/28 23:39:36 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[2021-10-28T23:39:37.1111720Z] [c50733655cbd] [Info] [ConfigurationService] Using port 34161 for connection.
[2021-10-28T23:39:37.1202562Z] [c50733655cbd] [Info] [JvmBridge] JvMBridge port is 34161
[2021-10-28T23:39:37.1220568Z] [c50733655cbd] [Info] [JvmBridge] The number of JVM backend thread is set to 10. The max number of concurrent sockets in JvmBridge is set to 7.
+------+-----+
| word|count|
+------+-----+
| .NET| 3|
|Apache| 2|
| app| 2|
| This| 2|
| Spark| 2|
| World| 1|
|counts| 1|
| for| 1|
| words| 1|
| with| 1|
| Hello| 1|
| uses| 1|
+------+-----+
It runs a command called spark-submit, which is how you submit jobs to Spark. You define what job class to run, master local (which is how you deal with clusters - in this case, running on local machine), the jar to run, and the dotnet command, which is where you’re mixing dotnet and JVM. And at the end is the input file input.txt.
Instead of running locally, you can have a driver which is the starting point for Spark, which then submits the job to a cluster. You can have this job execute on a cluster, with potentially hundreds of nodes or more. There’s a Kubernetes operator for it, so you can have the job run on Kubernetes if you want as well.
So how does VSCode figure into this? VSCode is not a traditional text editor, it’s a lot more than that.
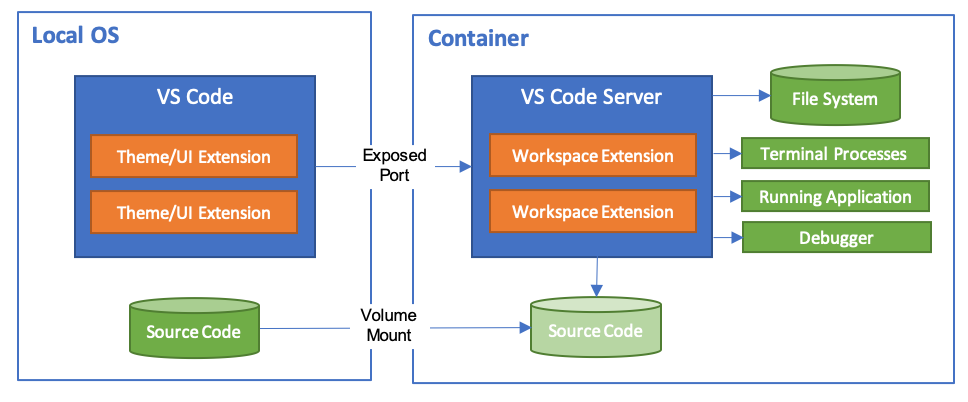
And in fact there’s an extension for it for remote editing. It starts VSCode in your local OS with your source code. And then you can attach it to your runtime, and then it mounts the volume of your source code into your runtime.
So you’re allowed to edit, debug, etc. on the runtime as it’s running. This way you’re allowed to have your own native environment running on your machine, but your runtime is inside your container. You don’t have to install all the dependencies locally.






{kind=link}